Associated with
7 min read
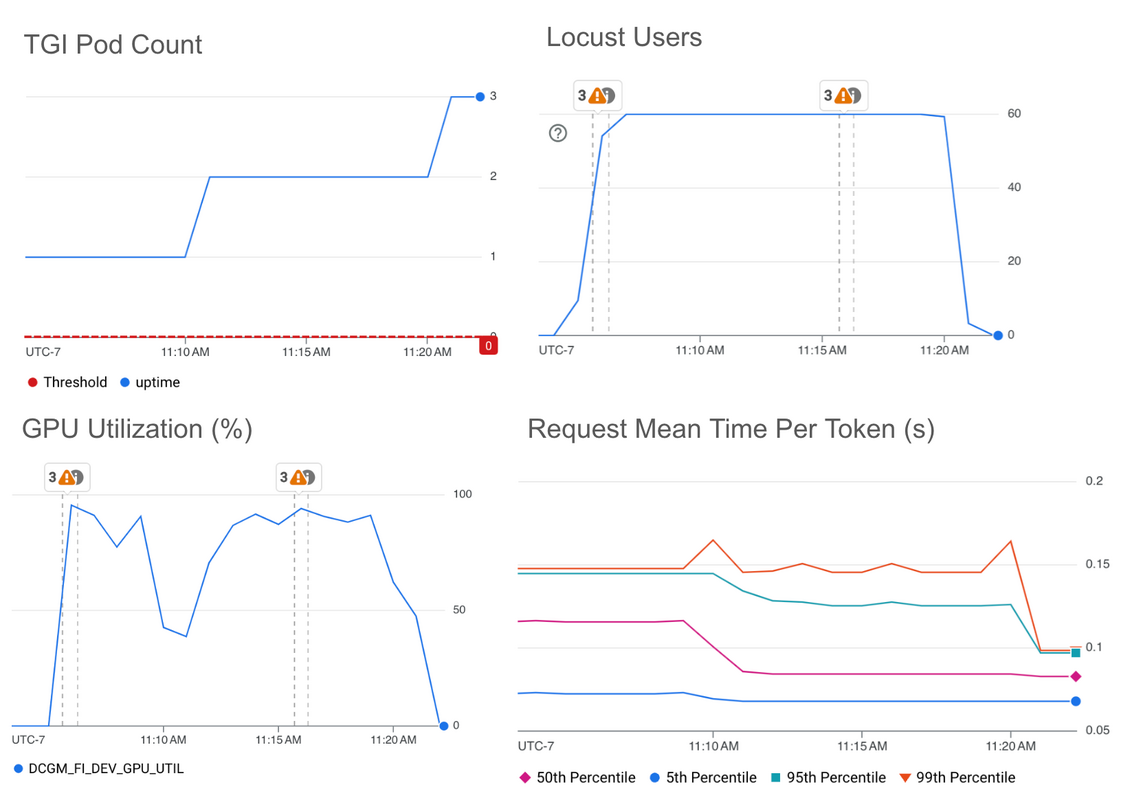
Save on GPUs: Smarter autoscaling for your GKE inferencing workloads
Learn how best to tune Google Kubernetes Engine (GKE) Horizontal Pod Autoscaler (HPA) settings to tune it for running an inference server on GPUs.
More Ways to Read:
🧃
Summarize
--
The key takeaways that can be read in under a minute
Sign up to unlock

Worth the squeeze
Get access to the condensed version of this piece, and every other article on The Juice by AudiencePlus, and so much more.
Start a free account on The Juice and we'll send you weekly emails sharing which podcasts, blogs, guides,
etc. are trending with other marketing or sales pros. We call it the Top 5!
Other content from
Google Cloud BigQuery




Featured by Salesforce
