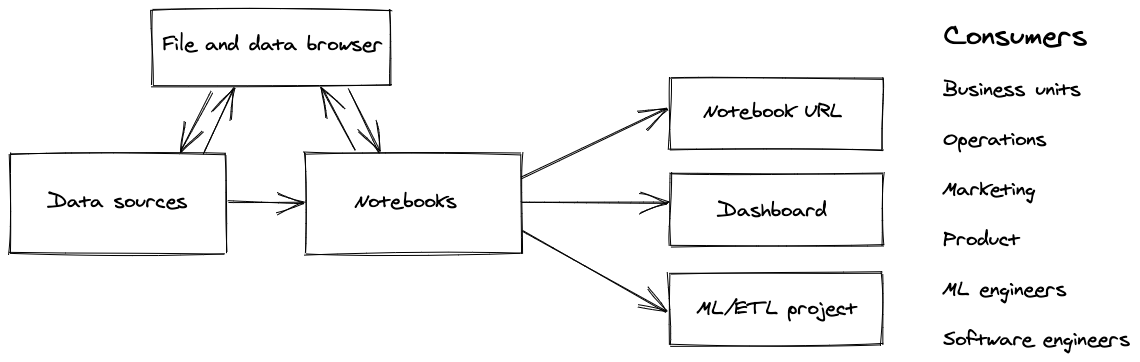
New data science and machine learning platforms are popping up almost every week. That's because vendors are building tools to optimize the data science workflow. They are creating better notebooks, making it easier to track the training of machine learning models, and facilitating the deployment of models or data apps in production. Along the way, they are often creating an end-to-end platform that covers everything from data ingest to productionization.
They are not, however, seeing mass adoption yet. Most data scientists still prefer to work locally with small data sets and free open source tools, and use email and manual handoffs of code to share their work. This workflow may be old school, but it's also convenient and familiar (and often cheaper on the surface!).
So how can you design a data science platform that will make them change their ways? In a nutshell, you need to match the efficiency of local development but also address its weaknesses, such as collaboration and reporting. If your tool can speed iteration cycles and make it easier for data scientists to showcase their work to external stakeholders, it should see rapid adoption.



")

